à noter, toutes les sessions auront lieu dans l’auditorium A1.
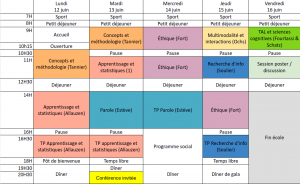
La formation consiste en 4,5 jours de cours magistraux et de travaux pratiques (50% cours, 50% TP) divisés en modules fondamentaux présentant les notions essentielles, les dernières avancées des méthodes statistiques et des modules liés au thème de l’édition :
-
- Concepts et méthodologie (Xavier Tannier, Sorbonne Université, UMR LIMICS) : Ce cours introductif présente les objets d’étude dans les domaines concernés, notamment les niveaux d’analyse de la parole et du langage, qui fournissent classiquement des informations pour les traitements applicatifs. Seront aussi abordées ici les méthodes classiques de traitement et prétraitement, les ressources existantes, les corpus oraux et textuels. Les problématiques d’évaluation dans différents contextes et applications seront également traitées.
- Apprentissage statistique (Alexandre Allauzen, Université Paris Sciences et Lettres, ESPCI, UMR LAMSADE) : Cette première partie consacrée aux approches par apprentissage automatique présentera les architectures de réseaux de neurones appliquées au traitement du langage naturel jusqu’aux transformers, en particulier dans le cadre des grands modèles de langage (Large Language Models, LLM). Le cours est accompagné de séances mettant en pratique les approches présentées sur des données de petite taille et la manipulation de modèles pré-entraînés plus larges.
- Traitement de la parole (Yannick Estève, Université d’Avignon, EA LIA) : Ce cours s’intéresse plus particulièrement à la reconnaissance et la synthèse de la parole à l’aide de méthodes neuronales. Il passe en revue les approches classiques et récentes et les illustres avec des cadres applicatifs. Ce cours est également accompagné de séances pratiques exploitant la bibliothèque SpeechBrain.
- Éthique et biais (Karën Fort, Sorbonne Université, EA STIH / UMR LORIA) : Ce cours sera consacré à la présentation des enjeux éthiques des recherches, que ce soit dans les pratiques méthodologiques, la création de données, leur exploitation, l’utilisation des modèles et la portée sociale de leurs applications. Les bonnes pratiques incluent aussi une prise de conscience des enjeux et moyens de la reproductibilité des recherches en TAL.
- Recherche d’information (Laure Soulier, Sorbonne Université, UMR LIP6) : Ce cours présente les problématiques et avancées du domaine de la recherche d’information, à travers les concepts de document, de requêtes, et d’interactions utilisateur. Le cours montrera la convergence entre le TAL et la recherche d’information et l’illustrera par des approches historiques et plus récentes. Ce cours est associé à des travaux pratiques à l’aide de Pyterrier.
La formation est complétée par des modules spécifiques au thème de l’édition :
-
- Développement du langage et TAL (Abdellah Fourtassi et Thomas Schatz, Aix-Marseille Université, UMR LIS) : Ce cours est consacré aux interactions entre TAL et sciences cognitives sur le développement du langage chez l’enfant. Il fait un tour d’horizon des concepts issus des sciences cognitives et présente les grands enjeux et problématiques liés à l’étude du développement du langage et de l’interaction conversationnelle chez l’enfant, s’appuyant sur les résultats et expériences à l’état de l’art, fondés sur le TAL. En particulier, ce cours explore une vision multimodale du développement du langage, et repose sur des activités pratiques exploitant des ressources de cette nature. Il discute en profondeur de l’idée d’informer la création des modèles de TAL par les résultats issus de sciences cognitives.
- TAL multimodal et interactions (Magalie Ochs, Aix-Marseille Université, UMR LIS) : Ce cours présente les fondamentaux de la caractérisation et de la synthèse d’interactions multimodales. Il permet d’explorer les modèles pour les agents artificiels manipulant le langage dans un contexte multimodal, en particulier d’un point de vue de l’interaction humain-humain et humain-machine, à travers les dernières avancées méthodologiques dans le domaine.
Une conférence invitée mettra en lumière la vision du domaine d’un chercheur prominent dans le domaine :
-
- Conférence (Hermann Ney, RWTH Aachen University) :
- Titre : Speech & Language Technology: Past, Present and Future.
- Résumé : Today data-driven methods like neural networks and deep learning are widely used for speech and language processing. We will re-visit the evolution of these methods over the last 40 years
and present a unifying view of their principles. Specifically the talk will focus on speech recognition and language modelling. - Supports : pageperso.lis-lab.fr/benoit.favre/files/HermannNey_Lecture_ETAL_CRIM_Marseille_OnWebsite_13Jun23.pdf
- Conférence (Hermann Ney, RWTH Aachen University) :
Un module optionnel permettra aux participants d’attaquer un problème concret en équipe :
-
- Hackathon (Benoit Favre, Aix-Marseille Université) : appropriation de la modalité visuelle par les grands modèles de langage. Une réunion journalière sera tennue à 18h après les cours. Les travaux liés à ce module sont décrits dans une page dédiée.